网站链接:
https://xunziallm.njau.edu.cn/
近日,面向古籍智能处理的荀子大模型正式通过国家生成式人工智能服务备案,并免费向公众提供对话服务界面(https://xunziallm.njau.edu.cn/ ),欢迎古籍从业人员和广大古籍爱好者使用!
荀子古籍大语言模型由南京农业大学王东波教授团队主导研发,是江苏省首个以高校为主体完成国家生成式人工智能服务备案的大语言模型。该模型依托南京农业大学的高性能算力基础设施支持,结合课题组在古籍数字化领域十余年的数据积累,实现了古籍传承与人工智能技术的深度融合。这一成果不仅彰显了高校在科研创新中的主体地位,也为江苏省大模型产业注入了学术化、专业化的新动能。
作为古籍智能处理领域的开创性成果,“荀子”是国内首个专注于古籍活化利用的垂直大语言模型。其核心功能涵盖古籍智能标引、信息抽取、诗歌生成、高质量翻译、词法分析、自动标点等场景。例如,模型可自动识别《史记》中的人物关系并生成知识图谱,或对未句读的文言文进行精准断句和翻译,极大提升了古籍在广大群众中的推广传播效率。此外,该模型的开源性、公益性特点,使其成为古籍活化的标杆工具,为古籍数字化研究提供了更加坚实的基础。
在全国范围内,荀子古籍大语言模型是第二个以高校为主体成功备案的大语言模型。研发团队依托国家社科基金重大项目,构建了覆盖《四库全书》等传世古籍的40亿字混合语料库,并通过创新的“古籍-现代汉语混合训练”技术,突破了通用大模型在古文理解与生成中的瓶颈。这一成就不仅填补了古籍领域大模型的空白,更标志着高校在人工智能技术攻关中的关键作用,为后续产学研合作提供了示范。
本站上线的对话模型是预览版的荀子2.0对话模型,由Qwen3模型基于长思维链古籍推理任务和通用古籍处理任务训练而来,同时支持深度思考和非思考模式,满足用户不同的古籍文献处理需求。用户在登录界面完成注册后即可使用荀子古籍大语言模型对话服务。

我们的微调数据集集成了文本翻译、文本标点、古籍文本补全、古代常识问答、信息抽取等近20项常见的古籍处理任务和通用对话任务,每项任务的触发指令都与模型在训练阶段所使用的指令一致。用户可采用下表的指令触发模型处理特定任务的功能。(建议在非思考模式下使用获得格式标准的输出,表中标红文本代表可修改的变量)
以“南京”为题生成一首古诗: | ||
当启动深度思考模式时,模型还能像Deepseek R1、Qwen Plus等推理模型一样完成更加多样性的、复杂的推理任务,欢迎用户自行探索模型的处理功能。
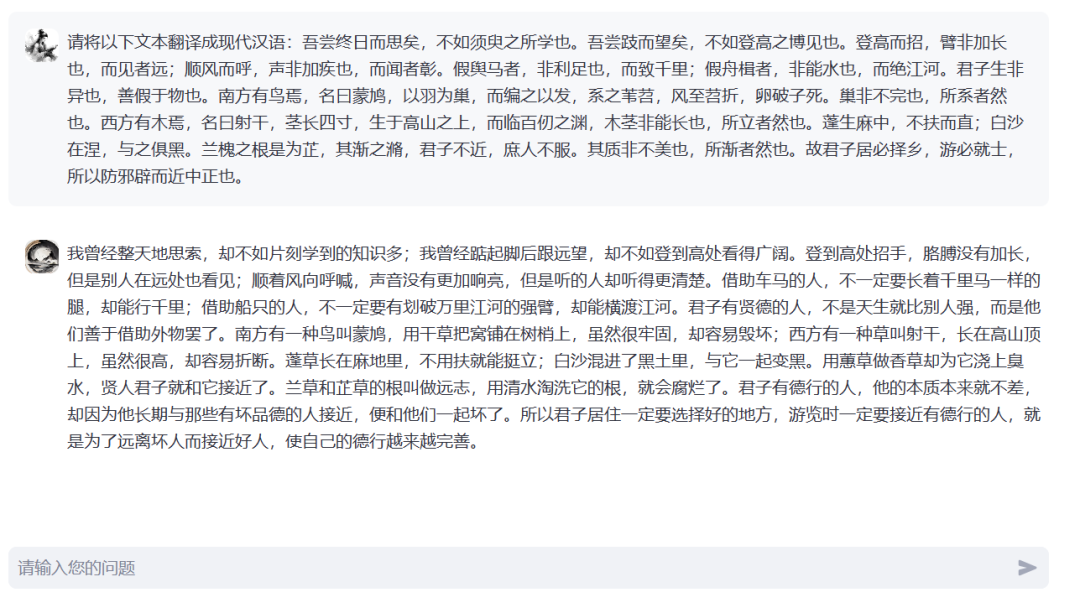

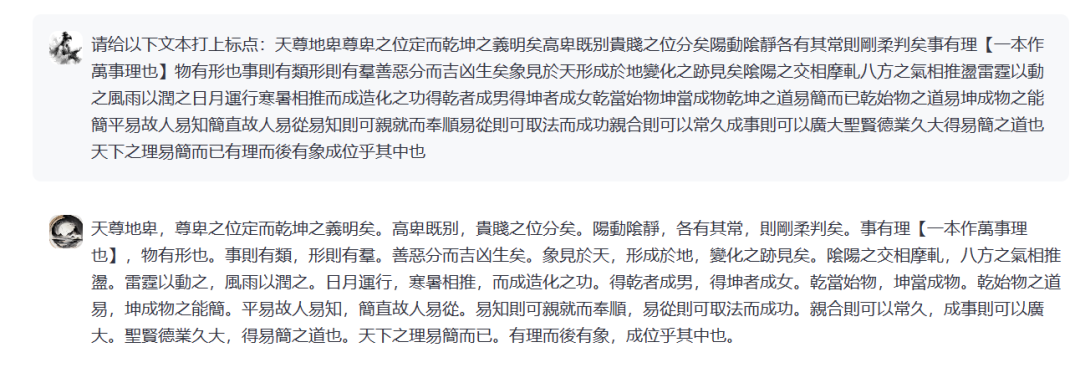
支持更多类型古籍处理任务的荀子模型正在持续开发中,欢迎持续关注本站!本项目的开源链接为:https://github.com/Xunzi-LLM-of-Chinese-classics/XunziALLM,如您有进一步的古籍资源开发需求,欢迎下载模型或与我们联系,您的批评和建议会成为我们不断追求卓越的动力!
相关链接
本篇文章来源于微信公众号: 比特人文