基础设施

陈逸云 / 搜韵网
吴 怡 / 四川大学中华文化传承与全球传播数字融合实验室
摘 要:人名广泛存在于古典文献中,提取人名实体对构建古典文献知识图谱至关重要。然而,称呼的多样性、高重名率、与地名和常用词汇的易混淆性、因前文而称呼从简、因交往亲近而称呼从简、因诗句长度而称呼从简、因文献缺失而难以推断,凡此等等,使得人名实体的提取困难重重,而且在甄别出某个字符串是人名之后,要对应到人物库具体人物上,也容易出错。本研究在详细剖析了以上难点之后,提出分类词典树分词和FAISS消歧相结合的方法,并将该方法应用到一百多万首诗词作品、九万多条人物小传和一万多种古典文献上,取得了三字人名识别准确率约92%,二字人名识别准确率约85%的效果;又借助作品题目中涉及人名描述的模式,从题目中自动发现了约6.8万个新人物;最后,基于此成果开发出诗文作品中人物互相提及的关系网,辅助人文学者从事人物关系和人物影响力的研究。
关键词:人名实体识别 标签化 知识图谱 实体对齐
时间、地名、人名是古典文献知识图谱中三个非常基本而重要的元素。这三个要素的提取,各有其难点。时间难在日期的推断上,地名难在沿革变迁的考证上,而人名,则恐怕是这三者中最具挑战性的。一是因为人名的数量要远大于纪时名称和地名;二是称呼的多样性和高重名率增加了识别和消歧的难度;三是诗文中常用省称且某些省称与常用词汇区分度不强,这都增加了识别和消歧的难度。由于人物总是生活在特定时期和特定地理空间,所以上下文的时间和地理信息,对消歧也起到了很大的作用。时间类实体信息的提取,在本人另一姐妹篇《古籍文献中纪时实体信息的提取方法及实现研究》论文中已有专门讨论。[1]地名类实体信息的提取,后续也将撰专文介绍。本文着重剖析人名实体信息提取的难点,并提出解决方案,以资参考交流。
中文命名实体抽取技术,自1990年代发展至今,主要可归纳为两种:一是基于词典和规则,二是基于机器学习。特别是后者,近些年来,诞生了很多解决方案。但是在古籍文献领域,还未见到卓有成效的成果。这主要是因为机器学习算法往往需要大量的样本,而古籍文献在这方面可提供的样本量,远远不够。对于前者,如果规则过于简单,则难以有效应对复杂多变的古代人名问题。鉴于此,本研究回到古代人名实体识别问题的起点,详细剖析其难点并提出词典、本体数据库、专名识别程序和FAISS(Facebook AI Similarity Search)[2]相结合的方法,实现了三字人名识别准确率约92%,二字人名识别准确率约85%的显著成效。在算法的分类上,本研究仍属于词典和规则一类。只是在分词算法和规则的设计上,更加灵活、更加有针对性。本文的研究成果,已开发成在线应用,详见https://cnkgraph.com/people。
本研究人物资料库及古典文献资料皆来自“知识图谱网”(https://cnkgraph.com)。其中历史人物76,820人,人物小传95,253笔,历代诗词作品约110万首,古典文献约1.1万种。[3]人物小传主要整理自《中国历代人名大辞典》[4]《全唐诗》《全宋诗》《全粤诗》《列朝诗集》《晚晴簃诗汇》《元诗选》《元诗纪事》《中州集》《御选元诗姓名爵里》《御选明诗姓名爵里》《明诗纪事》《清诗别裁集》《檇李诗系》《全台诗》《甬上耆旧诗》《江上诗钞》《词学图录》《闺秀词钞》《二十世纪诗词文献汇编》等。本章述及的人名信息提取难题,广泛地存在于上述诗词作品库和古典文献中。
(一)称呼的多样性
人除姓名之外,往往还有字、号、行第、官爵、职业、别称、郡望、籍贯、时代等信息。一些特殊人物,如君主或名臣,还有庙号、谥号等。人处于社会关系网中,又有梁章钜在《称谓录》中所举的各种称谓。凡此种种糅合在一起,构成了人物称呼的多样性。声名越著,经历越多,其称呼种类也越多。例如,白居易在各种文献中,不同称呼就有四十多种。表1列举了白居易除姓名之外的十几种常见称呼方式组合。
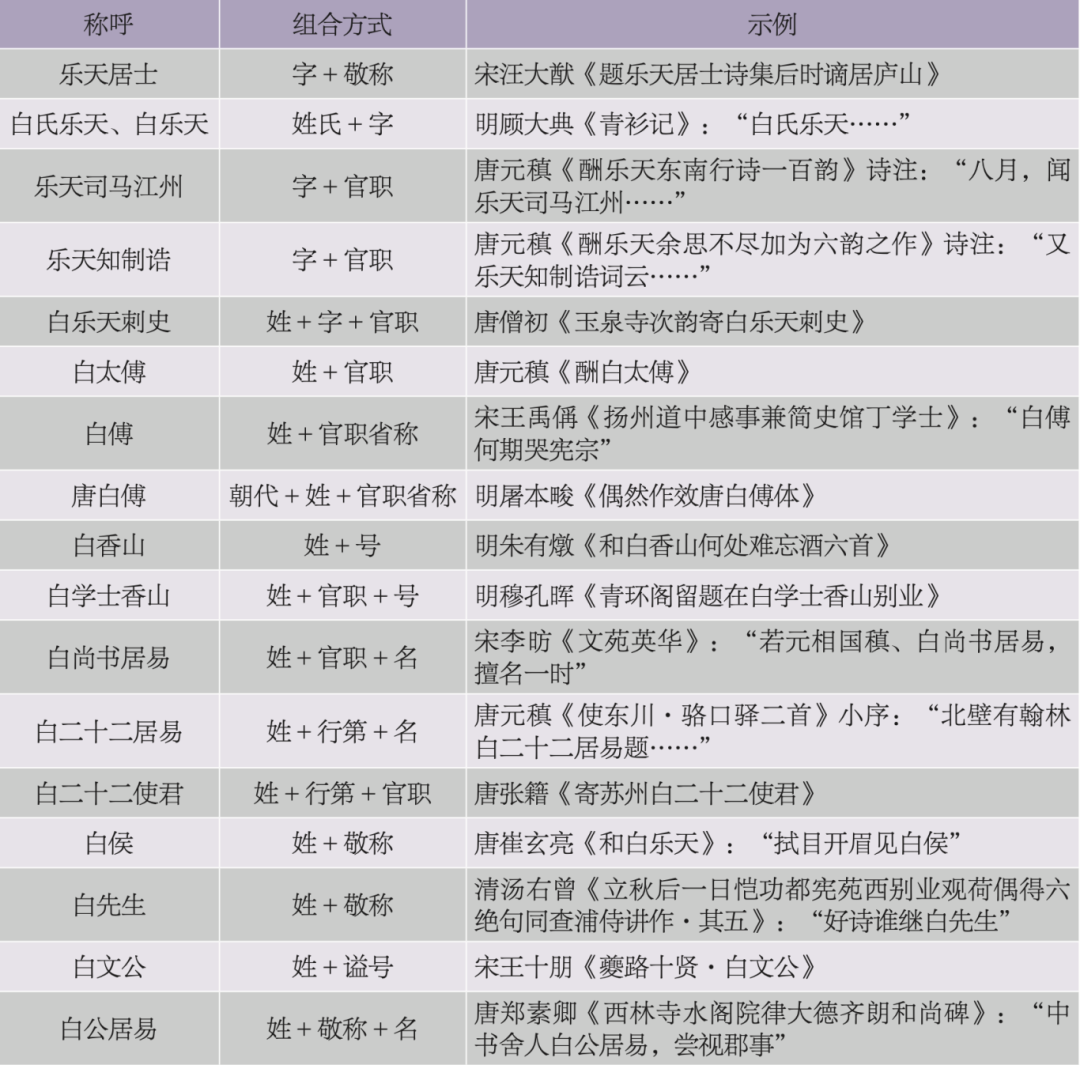
表1 白居易称呼多样性示例
还有很多其他的称呼方式,如“乐天白公”“白傅分司”“白醉吟”“白居易同年”“居易公”“白司马”等,篇幅关系,不一一列出。基本上来说,官迁一级,换任一地,都可能产生新的称呼。如刘禹锡因出知和州,白居易有诗《答刘和州禹锡》。刘氏改知同州,白氏又有诗《喜见刘同州梦得》。虽然称呼的多样性增加了人名实体提取的困难,但是这些多样的信息,也为人名的消歧提供了帮助。如五代贯休《怀钱唐罗隐章鲁封》,特指钱唐人罗隐,有利于消除因重名而产生的分歧。
除上述各种组合方式外,还有以下三种情况也值得注意:
一是帝王除称庙号、尊号等,还有用年号代称的情况。例如,明代《仙佛合宗语录》卷1“虽有大明嘉靖皇帝遍求请而不肯出”,用“嘉靖皇帝”代称明世宗朱厚熜。而实际上,这种情况在更早的时候就出现了,如唐马戴诗《府试观开元皇帝东封图》即用开元皇帝来代称唐玄宗李隆基。
二是后文称呼因前文而简化,如《史记·项羽本纪》“项籍少时,学书不成,去学剑,又不成。项梁怒之。籍曰……”,前已言项籍,后则只省作“籍”。又如清胡介祉《望是故乡行次毛子霞归郢》诗首句“毛生岂是鸱夷子”,题目已交代“毛子霞”,诗中便用“毛生”代指,这也属于因前文而省称的情况。
三是因篇幅、句子长度限制而简化。这类情况在诗中很常见。如曹魏嵇康《酒会诗》“钟期不存,我志谁赏”,“钟子期”省作“钟期”;唐卢纶《送绛州郭参军》“府趋随宓贱,野宴接王祥”,“宓子贱”省作“宓贱”;清释成鹫《霍子西牛卒于富春挽诗三章》“拟续刘标著论难”,“刘孝标”省作“刘标”;唐顾况《拟古三首》“浮生果何慕,老去羡介推”,“介之推”省作“介推”。凡此种种,人名中“子”和“之”字可省略,几乎成了惯例。更有甚者,隋王胄《答贺属诗》“本欲从张耳,何曾说马卿”,“司马长卿”直接省作“马卿”;还有陈思王曹植在诗中省作“陈思”,太史令司马迁省作“史迁”。
(二)重名率极高,消歧难度大
历史人物林林总总,重名几乎是不可避免的。以本文人物数据库76,820人为例,名、字、号等含有“子美”的,有34人,“伯玉”68人,“吉甫”72人,“文忠”73人;以“退庵”为号的,33人;封嗣“关内侯”33人,“赵国公”26人,“都亭侯”22人,“琅琊王”18人。君主的庙号,如“太祖”“太宗”之类的,重名的也极多,更有甚者,楚国国君,都可称楚王。遇到这些名称,消歧难度很大。然而,也有单字而不与人同名的,如“纣”,或因名声太坏,后人并不愿意使用。笔者统计了二字和三字称呼中,重名情况的占比,具体如表2。

表2 重名率统计
通过上表可看出,虽然重名非常常见,但如果是三字称呼,那么重名占比就快速下降到14.1%。古人在提及他人时,有时采用了比较冗长的称呼,这可能也是为了消歧。例如,有姓名和字并提的,如“张子苾祥龄”;籍贯与姓名并提的,如“山阳王粲”;行第与姓名并提的,如“高三十五适”。通过这种多样性的搭配方式,避免了重名的误会。
(三)一些名号本身也是常用词汇,难以与正常的行文区分开
与常用词汇相同的情况,在人物库中,并不乏见。著名的如黄庭坚号“山谷”,文徵明号“衡山”,刘禹锡字“梦得”,清朝兵部尚书“明珠”,道教始祖“老子”。三字的如“兰陵王”,既是封号,又是词牌名。这些词汇在诗文中出现的频率极高,不易消歧。
(四)姓氏与官爵称谓结合而引起的歧义
虽然能与官爵相结合而引发歧义的姓氏并不多,但是处理起来也颇为麻烦。例如,《全后汉文》卷43《何敞传》:“迁尚书,出为济南王太傅,迁汝南太守,免。”“济南王太傅”是济南的王姓太傅,还是于济南王处充当太傅一职?又如,明吴伯宗《寄奉左布政》诗,“左布政”是左姓布政官,还是任左布政使一职?此时不得不根据前文,才能得出正确的判断。
(五)因交往亲近而常称其号或字
这类情况在诗文中很常见。例如,数据库中宋及宋以前以无咎为名或字的有9人,韩元吉字无咎,与陆游交往甚密,多有唱酬之作。陆游有诗《次韵无咎别后见寄》,若非知道两人常有交往,几乎无法推定诗中所指的是哪一位无咎。晁补之也是字无咎,黄庭坚与他交谊深厚,常相唱和,黄庭坚有诗《奉和文潜赠无咎篇末多见及以既见君子云胡不喜为韵》,同样,若是不知道这层交往关系,就难以消歧。
(六)尚有大量人名,因文献或数据库资料不足,难以识别
一个好的解决方案,不应该只局限于能识别已收录的人名。对于文献资料不足或数据库未收录的人名,需要有发现能力,以便查漏补缺,进行补充。这类情况在诗文中很常见。例如,南宋陈必复有《奉酬陈介庵明府桐江见寄》,而数据库中尚未收录陈介庵的资料,那么理想情况下,应该至少能够识别出“陈介庵明府”这一称呼。又如宋陈师道《送提刑李学士移使东路》诗,“李学士”虽然不知何人,但应该能标示出此处为人物称呼。
图1是解决上述诸多困难的技术方案。从图中可见,虽然本文介绍的是人名实体信息提取,但在分词的过程中,其他诸如职官、时间、地理、植物和一般词汇的本体库,也很重要。一是可提供上下文信息,二是可提高分词的准确度。各个本体库定义了各类本体的属性,本体库中每个实体的各种属性值,构成了标识该实体的多元向量。从文本中提取各类实体的过程,主要分两步:一是分词切割文本;二是根据上下文及已切割的文本,由各个本体库的专名匹配程序,到本体库中搜索最佳匹配的实体。前者主要是在构建分类词典树后借助Trie算法[5]进行分词,后者主要是借助FAISS算法寻找最佳匹配。下面分小节详述人名实体提取和优化的整个过程。
(一)生成分类词典树
各类本体有各自感兴趣的关键词集。在人物本体专名匹配系统中,除了对已登记人物的姓名、字号、别称等信息进行精确匹配外,系统特别关注所有姓氏关键词的识别。这种设计主要基于以下考虑:由于人物称谓存在高度多样性,若采用穷举法对所有可能的姓名组合进行匹配,不仅会导致数据量呈指数级增长,还会降低系统的运行效率。因此,本系统采用了一种智能化的匹配策略:首先识别基础信息(包括姓、名、字、号等),然后结合上下文中的职官信息、地理信息、时间信息等特征,并依据称谓构成规则,用FAISS相似度检索方法在人物本体库中进行综合研判,最终提取相似度最高的人物实体。这种基于语义理解的匹配机制不仅显著减少了关键词的数量,还大幅提升了人名识别的准确性和系统的适应性。
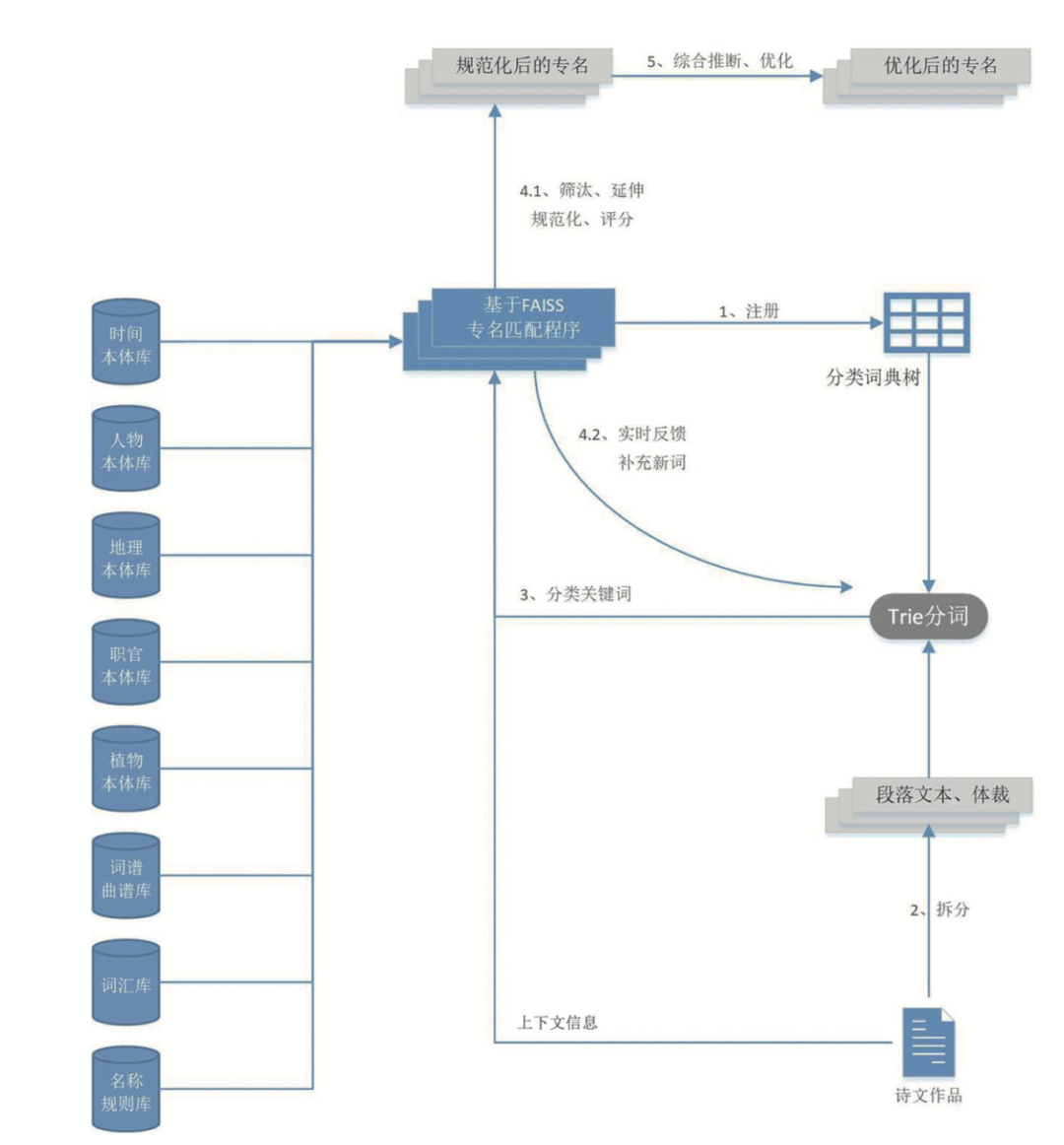
图1 基于分类词典树Trie分词和FAISS消歧的技术方案
纪时专名匹配程序主要对各种节日、年号、月、日关键词感兴趣,在Trie检测到相关关键词之后,由专名匹配程序根据上下文,对日期进行整合、推断。地理专名匹配程序则主要对古今地名感兴趣,在得到Trie的反馈之后,根据上下文以及行政区划的层级关系进行消歧、推断,如此等等。各个专名匹配程序把自己感兴趣的词汇集注册到分类词典树,构建出Trie分词的基础词典库。Trie分词之后,再根据各个关键词的类别,调用各个本体的专名匹配程序来处理。
(二)文本拆分
本研究处理的文本对象有以下三种:
第一种是已经结构化的诗词作品。结构化是指作品已明确标示出体裁、作者、朝代、标题、正文、序跋或注释等信息。部分作品还有创作时间和创作地点信息。诗词作品的文本拆分按上述各种属性分别进行。细致拆分的一个意义在于为各部分文本划定了最晚时间信息,以辅助消歧,例如,诗题和诗句源自作者,行文中若有提及人物,其生年绝不会晚于作者卒年。注释除自注外,则可能含有晚于作者出生的人物。另一个意义在于提高分词的准确率,例如,对于标识为七绝或七律的句子,一般可按223句式进行划分。所以南宋释元肇《和杨节使登径山》首句“阊阖门西湖水临”,虽然“阊阖门”和“西湖”都是地点,但是依句式结构,“西湖”出现的位置并不合理,从而舍弃,避免错误分词。
第二种是带句读的文本。这类文本多是来自已标点的各种电子书,文本的背景信息比较有限,往往只有作者和成书年代信息,对消歧有一定帮助。这类文本将按标题和段落进行拆分。
第三种是不带句读的文本。这类文本主要来自日本汉籍资料库[6],分词准确度较差。由于这类文本的标题不够明显,所以主要是按段落拆分。
(三)专名匹配与消歧
Trie按已注册的分类词汇表从文本中匹配到关键词之后,即调用各个类别对应的专名匹配程序进行处理。在调用时,还会提供相关的上下文信息,主要包括作者姓名、朝代、创作地点、体裁、段落文本类型(如标题、序、正文、注、跋之类),以及前一个已识别的实体。专名匹配程序根据已匹配到的关键词及这些上下文信息,生成多元向量,通过FAISS算法,到本体库中通过一系列的消歧,得到最佳匹配结果。消歧是本算法的重点,下面专门介绍本研究在人名实体信息提取中所采用的各种消歧方法。
1.借助人物本体属性进行消歧
人物本体的基本属性主要包括姓、名、字、号、行第、别称、谥号、庙号、生卒、朝代、活动年份、籍贯、曾担任的官职或曾获封的爵位、职业或身份、性别等内容。扩展属性则有知名度(被提及的次数)、亲密人物列表、各名号称呼与常用词汇的易混淆度、是否为典故人物、在文学作品中常用的称呼、曾以哪些方式被提及、在诗句中常相伴出现的词汇等。人物本体库的构建将在后面章节详述,本小节主要阐述这些人物的本体属性在消歧中的作用。
姓名、行第及各种字号、称谓、官职的组合,是最基本的消歧。在匹配方式上,取其交集即可。作者的卒年或朝代信息有助于界定作品中提及人物的时间下限,从而排除生年在作者卒年之后或朝代结束之后的人物。对于没有明确生卒年的人物,则主要是根据其活动时间和朝代来推断其可能的最晚卒年。籍贯一般只出现在称呼的前面。在消歧时,如“前一个已被识别的实体”这一上下文信息是地名,那么可加入多元向量,尝试以此地名作为籍贯信息进行消歧。官职或爵位则可能出现在姓之前、姓之后、名或字之后。例如,唐赵骅有诗《送晁补阙归日本国》,只从姓氏和职官,难以确定“晁补阙”具体所指。但由于后面有述及地名“日本”,则计算机结合籍贯及作者生卒时间,便可大概率推定是指曾在同时代任左补阙一职的日本遣唐使“晁衡”。
人物的知名度主要取决于其被提及的次数。例如杜甫在诗文库中被提及的次数多达9,180次,享有极高的知名度。所以诗文中提到“子美”处,优先考虑此处指的是杜甫。唯一的例外是,如果前文已提及另一人物,其字也是“子美”,那么判定为此处并非杜甫。例如,南宋白玉蟾诗《大都督制侍方岩先生召彭白饮于州治之春野亭因和苏子美韵》中有句“击缶吟招子美魂”,由于诗题已经交代了是和“苏子美”韵,所以在消歧时,会根据诗题推断此处“子美”指苏舜钦,而非杜甫。
亲密人物列表来自两部分:一是人物小传,二是作品中提及的人物。这个信息对消歧很有帮助。以前文所提及的陆游与韩元吉(字无咎)的关系为例,陆游有8首作品诗题包含“韩无咎”关键词,由此可确定与韩氏有亲密往来关系。有了这个信息之后,便可在消歧时推断陆游另两首作品《次韵无咎别后见寄》和《无咎兄郡斋燕集有诗末章见及敬次元韵》中所称的“无咎”是“韩无咎”,而非同时代的其他同名或同字者。值得注意的是,这种亲密关系可以是单向的,或者是跨时代的。就像杜甫和苏轼,常被后世作家同时提及,神交便是属于单向跨时代的亲密关系。
各名号称呼与常用词汇的易混淆度,来自以下两个信息:
(1)在某人物出生之前,其称呼用语曾在前代诗文中出现过的次数;
(2)如在诗词中某位人物的名、字或号频繁出现,却鲜少以其他方式连带姓氏一起被提及,那么这个名、字或号出现的次数越多,其与常见词汇的易混淆度也越高。
上面第一种情况是显而易见的,人不可能出生之前就出名。例如黄庭坚号“山谷”,“山谷”这一词,在他出生前已在其他诗作中出现了70次,这说明“山谷”这一称号与常用词汇的易混淆度比较高。但是,对于唐之前,乃至先秦的人物,由于现存历史文献本就稀少,难以提供充分的资料作为评估其姓名易混淆度的依据。这时,第二条规则就起作用了。正如前面所述,越出名的人,越会以多种方式被提起,所以,如果某个名号符合第二种情况,那么基本上行文中并非真的意在提及这位人物。例如南朝萧正立的名“正立”,东汉王辅的字“公助”,都属于这种情况。与常用词汇有高混淆度的,一般都会被淘汰,除非这位人物有高知名度,且与作者有前述的亲密关系。例如,南宋岳珂《米元章书山谷大悲憕赞帖》,虽然“山谷”是易错称呼,但是岳珂多次以其他方式提及黄庭坚,所以算法仍然能正确标识此处“山谷”指黄庭坚。
考虑到诗文常引经据典,所以在行文中如出现某些典故中相关人物的称呼,或者是文学作品中常用的称呼,或者是与某位典故人物常伴随出现的关键词,那么会被赋以更高的权重,增加其置信度,以协助消歧。例如,若是诗句中提到“马长卿”“马卿”,那么基本就是指“司马相如”,如提到“荆王”,基本就是指“楚顷襄王”。如提到“老子”,且诗句上下文有“牛”“函关”“紫气”或“五千言”之类的词汇,那么就可判定此处所指是道家创始人老子。与某一人物相关的词汇,可采用统计诗句中与该人物同时出现的关键词来获取。
2.借助实时反馈识别因前文而简化的人名
因前文已经提及而后文人名用缩略语的情况非常普遍,特别是在史书和赠诗中。本研究的解决方案是在识别到人名之后,实时反馈给Trie分词算法,临时注册、补充新的关键词,以便Trie在分析后文时发现这类简化的人名。但是,人名简称往往也易与正常词汇混淆,所以还需要控制好简称的时效问题。一般来说,对于历史类文章,人名简称往往会在紧随其后的段落中频繁出现,如果间隔若干段落该简称再被提起,那么此处有可能并非指代前文提及的那个人名。对于诗歌,诗题中提及的人名,有可能会在诗作内容中以简称的方式出现,而如果一个人名是在诗句中被提起的,那么鉴于诗句内容的跳跃性比较大,则通常不会出现跨句出现的人名简称。
3.借助含人名文本段表达范式发现新名
本研究的人物库只包含76,820人,尚有大量的人物未收录。理想情况下,人名提取程序,应该具备标识新人名的能力。目前的人名匹配程序,已经具备了通过姓、名、字、号和职官等基本元素采集称呼的能力。要实现新名识别,一是要让计算机能够识别看起来像人名的汉字组合,二是要让计算机能够识别与人名相关的表达范式。高重名率的特性,恰好可帮助计算机识别哪些汉字组合看起来像人名。而与人名相关的表达范式,用已标识出人名的标题作为样本,便可统计得到。例如,明邵宝《寄庄定山》诗,庄是常见姓,数据库中共有四位人物,其字或号是“定山”,因此,虽然数据库并不知道庄定山是谁,但是也可推断出这可能是个人名。再结合这个标题符合“寄<人名>”的表达范式,便可辨识出,这应该是一个与作者同时代的人物。又如明周是修《清隐堂歌为安城王使君赋》诗,“安城王使君”符合“籍贯+姓氏+尊称”的称呼范式,前后又符合“为<人名>赋”的表达范式,所以可断定此处是人物称呼。通过统计,本研究共得到含人名的常见表达范式705个。通过这些范式及称呼组合习惯,共识别出未收录人名约68,340个。
4.其他消歧方法
本研究还应用到一些其他消歧方法。例如,按行文习惯一般不直接称呼对方姓名。即便是长辈对晚辈,虽然可以直接呼名,但是一般也多是称对方的字或号。皇帝则是个例外。一般皇帝对臣子,都是直呼其名。根据这一特点,消歧时可降低那些直呼其名的情况的权重。另外,人物亲属关系也对消歧有帮助。由于目前数据库尚未建立完备的人物亲属关系图谱,因此,目前本研究仅非常有限地通过父子关系协助消歧。例如元代董文直人物小传:“元真定路藁城人,字彦正。董俊子。”与“董俊”重名者有二人,通过这一父子关系消歧,即可锚定具体是指其中哪一位。
(四)综合推断和优化
局部上下文信息毕竟有其局限性,有时难以完全消歧。在完成所有的局部消歧之后,对于仍有歧义的,可通过综合全文多条线索来消歧。一是时间线索,二是人物线索。这对于述史一类的文本非常有效。根据全文提到的各种时间标签,可消除那些生卒年背离时间线的干扰项。如果文中并没有明确的时间标签,那么可根据已经确定的人物推断该段文本所述年代,也可通过人物关系来消除干扰项。
人物本体库的构建与专名实体信息提取技术是相辅相成的。人物本体的主要属性及构建过程,如图2所示。
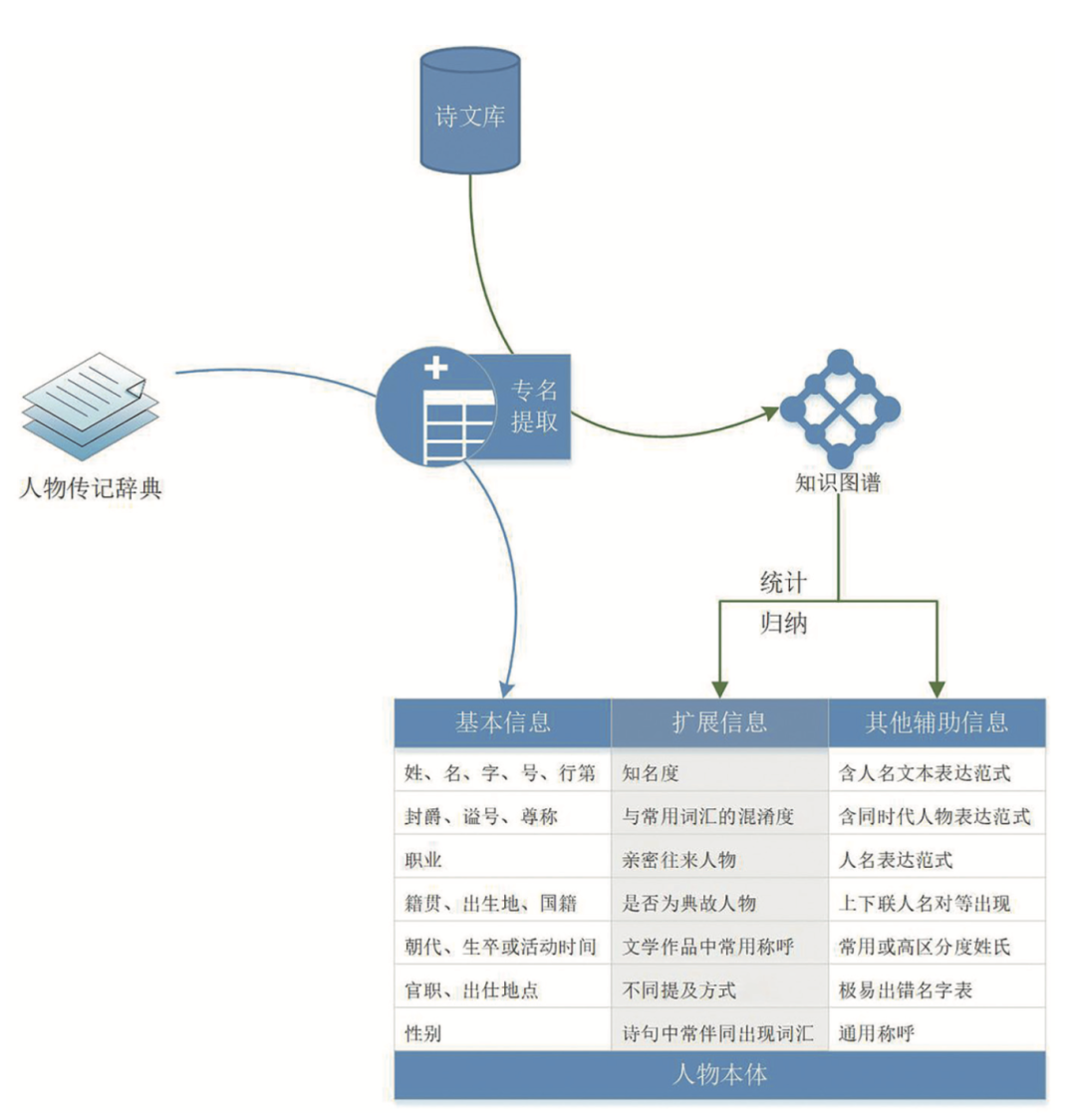
图2 人物本体主要属性及构建过程
借助时间、人物、职官、地名等专名实体信息提取技术,分析人物传记资料,可通过自动化的方式,构建出人物基础本体库;反过来,人物基础本体库又可支撑、优化专名提取程序,使其能识别更多形式的称呼。本项目正是通过这种本体库与专名提取技术相互促进、多轮迭代开发的方式,逐步建立和完善各个本体库与专名提取程序。以人物本体库为例,借助各种名称的表达范式,可从人物小传中识别出人物的字、号、别称、行第、封号等。同样,通过生卒年的表达范式,以及行文中提及的活动时间,可得到与人物相关的各种时间信息。借助籍贯的表达范式,又可自动提取出人物的籍贯、国籍等信息。职官、出仕地点等其他信息也类似,不再赘述。对于个别机器识别有错的,或者是机器不易处理的,则通过人工修正。总体来说,人工修正只是非常少的一部分,主体是由计算机自动完成的。
上图中人物本体的扩展信息和辅助信息,则是通过对整个诗文知识图谱进行统计、归纳后得到的。同样,这是一个多次迭代、逐步优化、互相促进的过程。归纳统计结果所产生的扩展和辅助属性,可支持人物专名识别程序,提高其识别能力和整个知识图谱的精度。识别能力和精度的提高,又进一步优化了统计和归纳成果。人物本体的各个属性含义,详见前文,在此不再赘述。
从前面所述及的人物称呼多样性和与普通词汇的易混淆性可看出,传统以关键词为主的检索方式,既难以一一穷举,又容易引入很多不相关的检索结果。本研究成果在一定程度上已经解决了这两个困难。现在计算机已具备了甄别同一作者多个称呼的能力,能理解像“陶潜”“陶靖节”“陶令”“五柳先生”“陶元亮”等称呼,指的是同一人。这大大方便了从事人物专题研究的学者。例如,在知识图谱网搜索“陶潜”可得结果如图3。来自诗库、人物库、古籍库的文本,不论以何种称呼提到陶潜,都已分类标识出来。
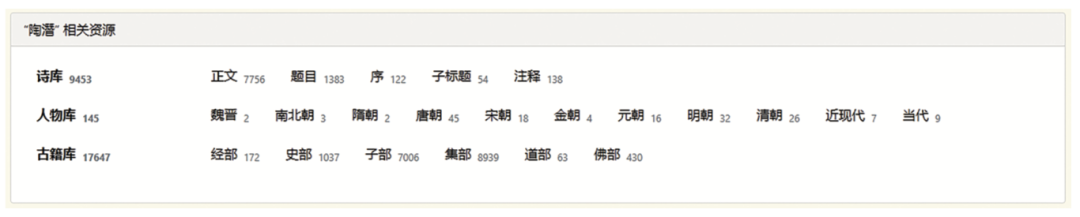
图3 知识图谱网与“陶潜”相关资源概况
一位著名作家会被后人在作品中不时提起,同时,这位作家的作品也会提及某些古人。以作家为中心,以朝代为横坐标,选取各个朝代在提起次数上排前20的人物,可直观地展示指定人物对后代的影响力,以及这位人物所心仪的前代人物。图4仍以陶潜为例。陶潜左边的,是陶潜作品中提及的人物,右边则是提到陶潜的主要后辈人物(为避免界面过于混乱,对于提到的数量比较少的人物,只有当把鼠标移到圆点上面才显示具体人名)。从图中可见,在宋代,以苏轼、赵蕃与方回在作品中提及陶潜的次数最多。
那具体是在哪些作品中提及陶潜的呢?这时点击左上角的“导出Excel”,即可看到图5所示的数据。
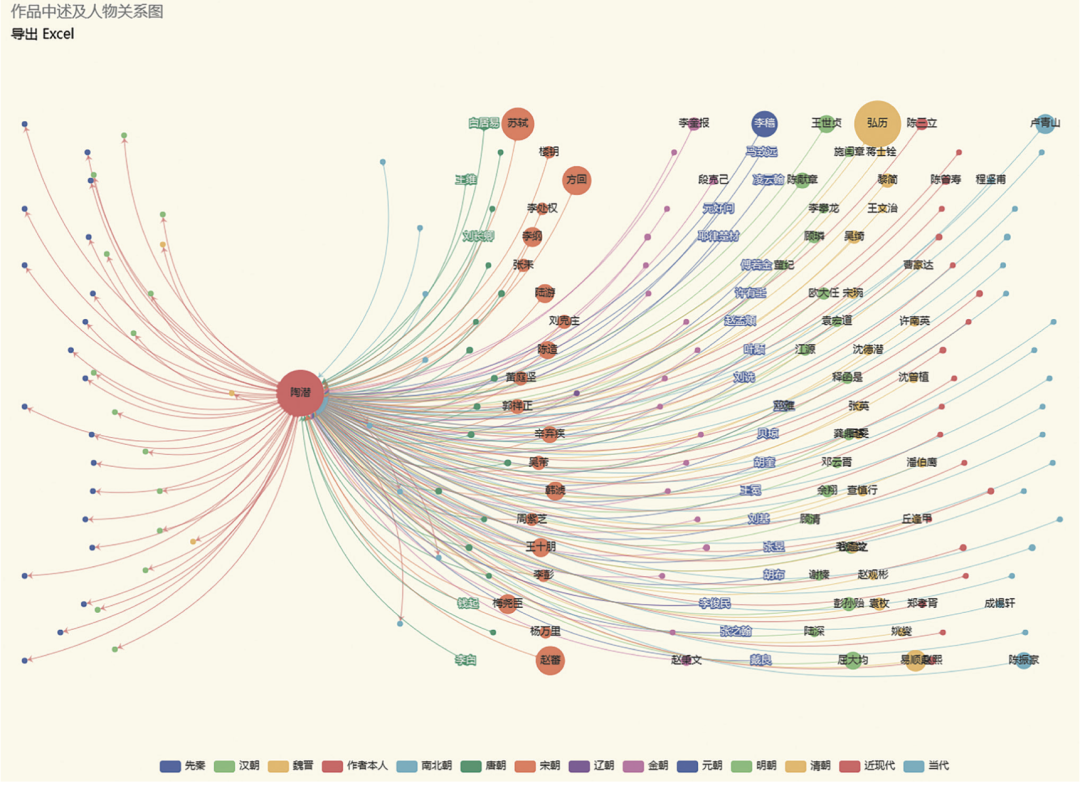
图4 陶潜对后代作家的影响力图示
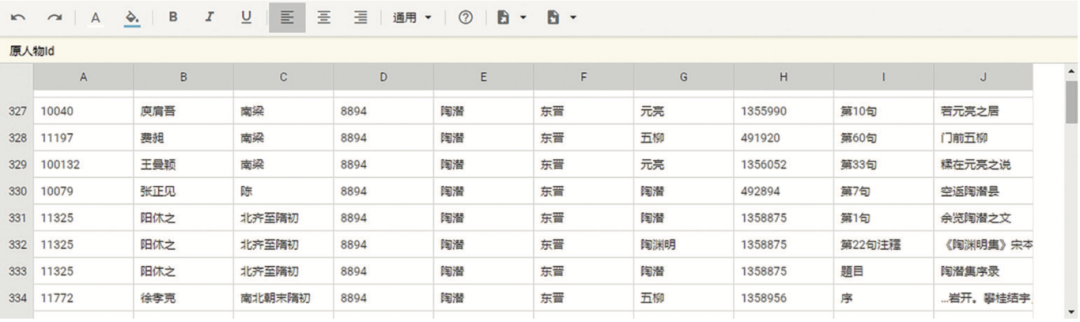
图5 陶潜影响力数据导出示例
导出之后,学者通过G列“称呼”一栏,即可看到本系统在标识陶潜时,都已经考虑到了哪些称呼方式。通过这个应用,可大大节省人物专题研究者搜寻资料的时间。支持直接把结果导出为Excel表,又方便了学者在此基础上,进行二次筛选或统计。
由上可知,从古籍文献的文本中甄别出人名字符串这一工作本身已属不易,而要对应到人物库中具体的人物,则更是困难。本文全面地剖析了提取人名实体信息的各种困难,并提出了分类词典分词和FAISS相结合的解决方案。就准确率来说,各个朝代的文本准确率会有所不同,越是后期的准确率越低。这是因为随着时间的推移,历史人物数量越来越多,其重名率也大大提高,再加上本研究人物库所收录的人物数也比较有限。三字或以上的称呼其识别准确率要明显高于二字称呼,这同样也是因重名率的不同而引起的。从各个朝代随机选取1,000个样本进行统计,本研究成果三字称呼的识别准确率约为92%,二字称呼约为85%。如果抛开人名与具体人物的对应关系,只是考察计算机是否准确地识别到文中述及人名,那么准确率则可达到97%左右。未来的主要改进方向,一是扩大人物库收录数量,二是借助CBDB(China Biographical Database)[7]一类的人物传记库中记载的人物关系,增强借助亲属关系消歧的能力。
Research on the Person Entity Extraction Model and Application in Ancient Documents
Chen Yiyun, Wu Yi
Abstract: Extracting person names from ancient documents is crucial for building the Chinese ancient knowledge graph. This task is challenging due to factors like naming flexibility, high duplication of names, difficulty distinguishing from common words, use of abbreviations, and lack of materials to properly identify individuals. This paper addresses these challenges and proposes a solution using classified Trie and FAISS algorithms to extract and map person names accurately. A web application was developed after processing over 1.1 million poems, 95,253 biographies, and approximately 11,000 ancient books. The accuracy is 92% for three-character names and 85% for two-character names, based on 10,000 samples. Additionally, leveraging patterns of person name descriptions in poem titles, the method automatically identified approximately 68,000 new individuals. Finally, based on these results, a web application was developed to visualize networks of mutual mentions of individuals in literary works, assisting humanities scholars in researching interpersonal relationships and influence networks.
Keywords: Chinese Person Name Entity; Labeling; Knowledge Graph; Entity Alignment
编辑 | 许可
本文是国家社会科学基金重大项目“汉魏六朝文学编年地图平台建设”(19ZDA253)的阶段性成果
[1]《古籍文献中纪时实体信息的提取方法及实现研究》,《数字人文》2022年第3期。
[2]FAISS是由Facebook AI 团队开发的开源数据库,主要对高维向量提供聚类以及检索方法。
[3]本文数据截至2023年11月。在此后的一年多时间里,知识图谱网站经历数次更新,数据量又有显著提升。
[4]张㧑之、沈起炜主编:《中国历代人名大辞典》,上海:上海古籍出版社,1999年。
[5]Trie算法,即字典树,是一种树形数据结构,一般用于存储和检索字符串数据。
[6]日本汉籍资料库官方网址见https://www.kanripo.org/,2024年12月1日。
[7]CBDB,即中国历代人物传记资料库,是由哈佛大学费正清中国研究中心、北京大学中国古代史研究中心、台湾“中研院”史语所共同开发的,截至目前,已收录64万多人的传记资料,官方网址见https://www.inindex.com/biog,2024年12月4日。
如需购买《数字人文》期刊,请扫描下方二维码

校对 | 肖爽
美编 | 王秀梅

往期回顾
本篇文章来源于微信公众号: DH数字人文