中国古代典籍实体自动识别模型和工具
刘江峰,冯钰童,王东波,胡昊天,张逸勤
【研究背景】
近年来,深度学习技术日益成熟,诸如LSTM、BERT模型及其变体在命名实体识别领域均有很多成功的应用。但由于语法上的独特性且与现代汉语、英语存在较大差异,汉语古文语料的分词、词性标注、命名实体识别难度较大。2018年Google发布基于双向Transformer编码器表征的语言模型(BERT)。在BERT模型中,一个已经过大量语料预训练的预训练模型能使模型的下游应用效率更高:只需一个额外的输出层就可对已有的预训练模型进行微调,并能应用在各类领域中,无需根据特定任务对模型进行实质性修改。BERT发展了预训练-微调的语言模型研究新范式。
《四库全书》是我国古代最大的文化工程,完整呈现了我国古典文化的知识体系。近日由南京农业大学信息管理学院牵头,南京师范大学文学院参与,使用《四库全书》繁体版本语料分别在Bert-Base-Chinese和Chinese-RoBERTa-wwm-ext(下文简称“RoBERTa”)上进行继续训练的SikuBERT、SikuRoBERTa发布。该研究在基于《左传》语料的自动分词、词性标注、断句、命名实体识别等下游任务上作了简要验证,效果较上述3个预训练模型均有不同幅度的提升。因此,本文尝试利用Bert-base、RoBERTa、GuwenBERT、SikuBERT、SikuRoBERTa等BERT预训练模型,以《左传》《史记》《汉书》《后汉书》《三国志》等为实验语料,对人名、地名、时间词等3种历史事件的主要构成实体进行识别,进一步探究SikuBERT、SikuRoBERTa在不同典籍、不同规模、不同语体风格语料上的泛化能力并作可能的改进尝试。
【实验设计】
研究框架
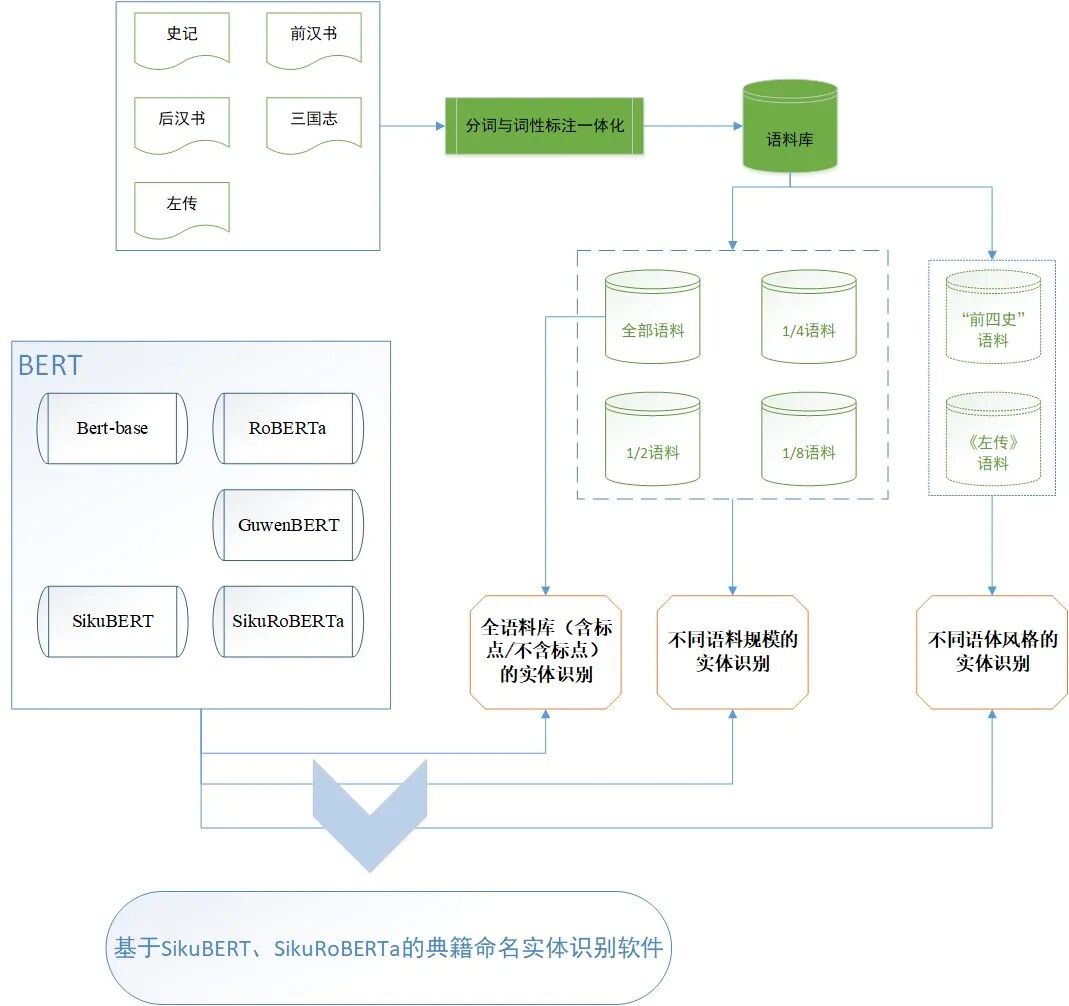
数据
《左传》以比较原始的材料相对全面地反映了春秋时期的政治、经济、文化等方面的情况,是现存有关春秋时期历史社会的最珍贵史料。《史记》《汉书》《后汉书》《三国志》合称“前四史”,是对中国各民族进行系统记录与研究的重要史籍,其民族传记开创了统一多民族中国历史的叙事范式,最早揭示了各民族之间的矛盾、交流和交融,对于后世有着重要而深远的影响。本研究所采用的训练语料是基于人工分词和词性标注并经过多轮校对的上述5种典籍文献,语料中包含标点符号。
对典籍文献的标注采取分词与词性标注相结合的方式,使用“/”进行分词,使用人民日报标注语料库(PFR)的词性标记标签标准,其中本研究所需要的人名、地名、时间词标记如表1所示。标注示例:董仲舒/nr 以為/v 先/n 是/r 四國/n 共/d 伐/v 魯/n ,/w 大/v 破/v 之/r 於/p 龍門/ns 。/w
【实验结果】
本文在BERT-base、Chinese-RoBERTa-wwm-txt、GuwenBERT、SikuBERT、SikuRoBERTa上进行了测试。实验分别在含标点、去标点、不同规模单文献、不同语体风格语料上进行了测试。
表1
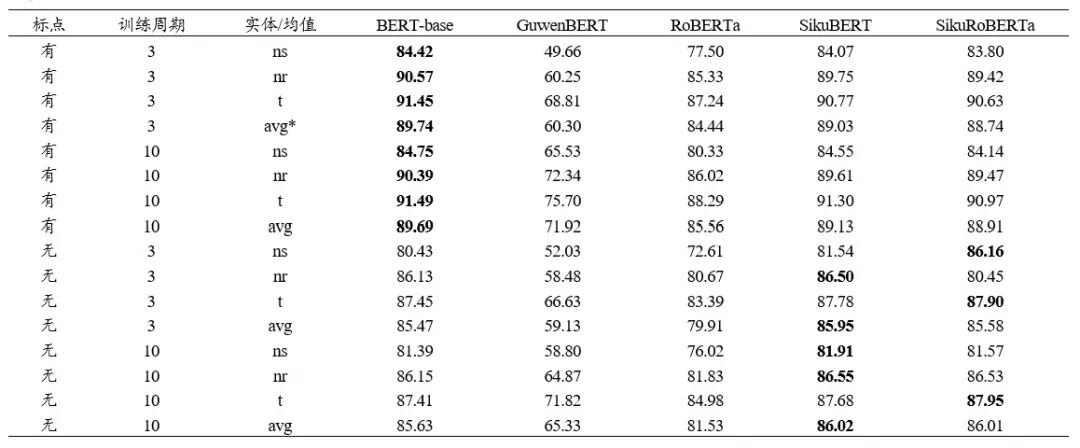
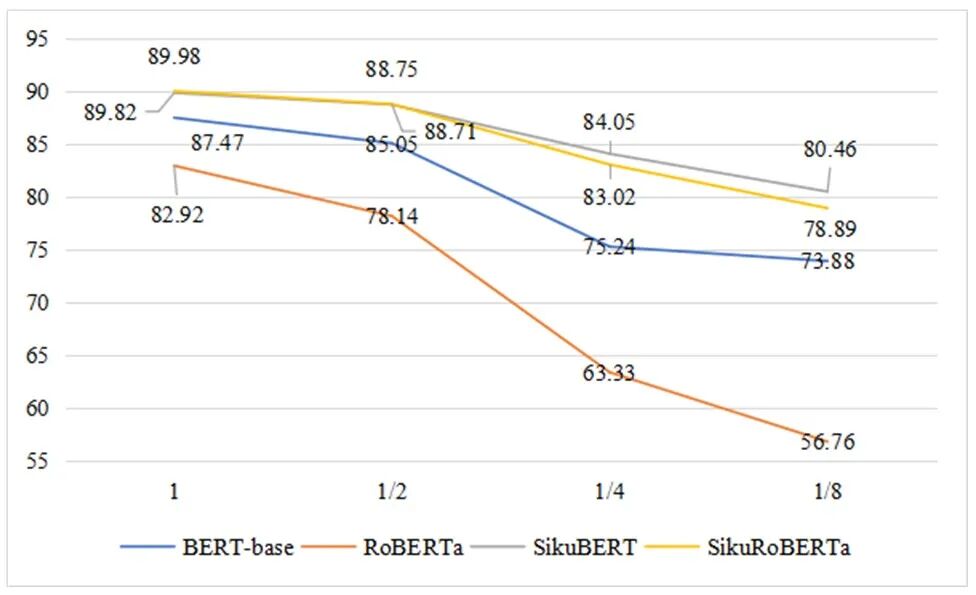
图1. 不同规模大小的语料实体识别效果比较
结果表明,Siku系列模型在去标点繁体语料上表现优异,SikuRoBERTa模型较SikuBERT模型在大规模语料上的表现更为稳定。
【应用展示】
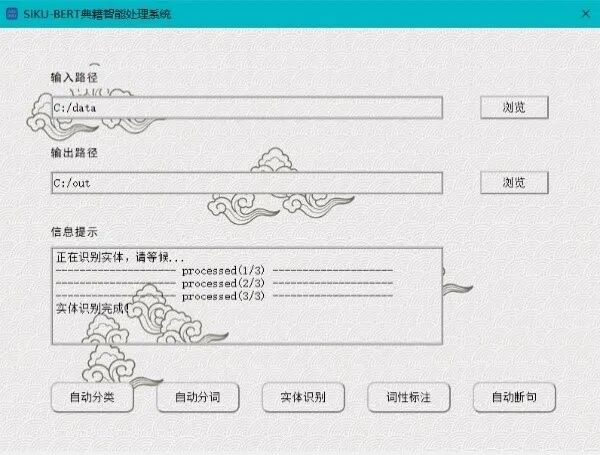
本实验构建了一个基于SikuBERT、SikuRoBERTa的命名实体识别应用系统,集成了分词、词性标注、断句、实体抽取、自动标点等常见古籍智能信息处理功能。该系统旨在帮助古籍研究学者更好地快速了解典籍,以推动研究的深化。具有两种语料输入模式:单文本模式和语料库模式,如图3所示。单文本模式可以即时输入和处理文本,语料库模式能对多个语料文件进行识别。SIKU-BERT典籍智能处理系统可以识别人名、地名和时间3类经典实体。


【相关发布】
论文地址(CNKI):
https://t.cnki.net/kcms/detail?v=MBOlVqmt0McCf946_ycryC-eqZuKTBZPNB_U7wlp7niGWe1ZmW3-nZ_tZFA2JPxZtnB6neMgMcQ71L62GbdJKa7qLrTPVJhdvZ-hvqrAtJfajTfYcsE5Qw==&uniplatform=NZKPT
预训练模型Github地址:
https://github.com/hsc748NLP/SikuBERT-for-digital-humanities-and-classical-Chinese-information-processing
往期回顾:

本篇文章来源于微信公众号: 比特人文