《中日文化交流史》第62期
数据驱动:当代日本史学的数字人文研究范式
王侃良、战林泽

2007年,吉姆·格雷在其演讲中提出了基于数据密集型计算的“第四范式”正在成为未来科学研究的主流的预言。如今,随着人类社会发展的数字化转型趋势越发显著,他的预言也在逐步走向现实。数据驱动(Data Driven)型研究也愈发得到各界的关注,来自不同领域的研究者聚集在新范式周围共同推动学术实践走向深入。尤其在本文所探讨的日本史学及其相关的日本人文学科领域,来自政府的支持至关重要。以2016年日本内阁会议提出“社会5.0”(Society 5.0)战略发展愿景为起点,日本学术振兴会、文部科学省、日本学术会议等机构与学界通力合作,纷纷推出大型项目。当下日本正以国家政策为导向,推动“数据驱动”科研范式的发展。
这种范式究竟“新”在何处?又为何得到追捧和倡议?
首先,“数据驱动”是以数据为“新”。在传统范式下,历史学的研究方法是搜集史料、分析史料、得出结论。数字化手段的运用停留在检索和阅览方面。而数据驱动型研究试图通过统计分析以及人工智能的大数据分析手段为学界提供新发现。对数据的处理、存储、分析与可视化成为科研中的核心活动,是基于数据展开的研究。
其次,发展“数据驱动”型研究不仅要引入新的研究方法,更需要建设统一的、相互关联的数据基础设施,将研究数据向全社会、全世界开放。
最后,于人文学科而言,新范式能够提供更加便利的研究环境,创造研究成果可复现、检验的基础与跨学科交流场所,以及提升学术成果国际传播水平的手段。于社会而言,新范式能够提供持续保存各种历史文化遗产的条件,促进人文学科研究成果在全社会范围内循环利用的机制。由此看来,“数据驱动”新范式不仅契合发展同信息社会相适应的人文学科之长远需求,更具备无法忽视的现实意义。
数据驱动的科学实践由采集、管理和分析三个基本活动组成。而在这三个相互关联的活动当中,数据本身正是动力所在。本文旨在追踪数据在当代日本史学研究当中的循环流动过程,整理日本学界在数字史学领域的尝试。但由于在具体的实践当中,数据的采集和管理常常紧密相连。而历史学对数据的利用并非仅限于分析数据以得出结论,有时更包含面向社会的教育与传播活动。因此本文将按照数字史学实践当中的实际工作流(workflow),把相关活动划分为历史数据的“输入、发现、利用”三个环节,并从这三方面评介日本学界的成果。
一、数据输入
数据输入,是“数据驱动”型史学实践的开端,更是整个实践过程当中成本最高、最重要的环节。对历史学而言,该环节意味着将实物材料转换为研究者可利用的电子文本或图像,乃至结构化数据。换言之,数据输入的过程包含数字化(Digitalization)与数据结构化(Data Structuring)双重环节。在这一过程当中,保证数据的准确性,使用统一的形式表示数据,并以通用的格式共享数据是日本学界一直以来面临的问题,也是其在数字化和结构化领域持续开展数字人文实践的锚点。
1. 数字化领域的实践
数字化方面,由于日语的书写系统主要由汉字和假名两部分组成,加之前近代日语典籍更是包含许多现代日语已经不再使用的字符,所以字符处理成为日本学界面临的首要课题。
首先,尽管截止至2023年发表的Unicode(统一码)15.1版本已经包含97681个汉字,基本消除了一般古籍转写过程中的缺字问题。但大量生僻字的加入,却产生了难以录入的问题。2017年守冈知彦开发的CHISE(CHaracter Information Service Environment)对解决此问题颇有成效。该程序将字型结构数据、发音数据、含义数据和字符集编码相结合,并在网络公开了“汉字结构信息检索数据库”,帮助转写者通过输入汉字部件查找特定生僻字,因而被广泛应用于史料数字化。
其次,1900年日本政府修改《中小学校令施行规则》前,日语中除平假名、片假名外,还存在着大量被称做“变体假名”的其他形式假名。变体假名如今已不再出现在一般社会大众场合,但在转写古籍和排印历史学学术书籍方面仍有用途。为使计算机能表示这些变体假名,2009年日本国立国语研究所启动相关调查项目,最终制定“学术信息交换用变体假名”, 并于2017年成功将286个变体假名加入Unicode标准当中。
在字符处理之外,光学字符识别(OCR)同样是日本学界在数字化领域努力推动的方向。近代以后的印刷体文献,机器识别难度并不高。截止至2022年,由日本国立国会图书馆委托外部公司开发的最新版“NDLOCR”在识别大部分近现代文献时其F值(F-Measure)达到了0.95以上。而且NDLOCR早已被用在日本“国立国会图书馆数字收藏”的全文检索功能上,效果有目共睹。但在包含大量“崩字”的前近代文献中,机器识别困难重重。现有各种OCR系统的表现均不容乐观。
目前针对该类日语文献的识别主要有三种已经面向外部公测的解决方案:一是由日本人文学开放数据共同利用中心(CODH),基于KuroNet改进而来的深度学习模型RURI及其移动应用程序“みを”;二是由TOPPAN公司开发的“ふみのは”;三是由日本国立国会图书馆开发的实验性OCR程序“NDL古典籍OCR”。为检验以上三个系统的识别效果,本文随机选取了一份江户时代文献进行测试,结果详见图一。

图 1 各OCR系统文字识别、布局分析结果对比
注:①为原图,②“みを”的结果,③为“ふみのは”的结果,④为“NDL古典籍OCR”的效果
表 1 各OCR系统评估结果

根据图1可知,“みを”和“ふみのは”在古文书的布局分析方面不尽如人意,有明显的漏列现象,“NDL古典籍OCR”则在此方面没有问题。根据实际识别出来的文字结果计算以上三种OCR的评估指标(如表1所示),可以发现即便是这三种中综合能力最强的“NDL古典籍OCR”,其F值也仅有约0.6626。换言之,若以该文献风格的史料为测试对象,即使使用“NDL古典籍OCR”识别,也很有可能至少有1/3的内容识别错误(或被遗漏)。如此低质量的文本显然无法直接用于研究。
为弥补OCR系统的表现不佳,日本学界另外采用众包手段促进历史文献数字化。其中最重要的成果莫过于由京都大学古地震研究会开发并运营的“大家来翻刻”平台。该平台主要由桥本雄太负责开发。其一大亮点在于桥本设计的标记语言(Markup Language)“Koji”。该标记语言十分简单易学,能满足描述日本前近代文献(古文书、古籍)中常见的“注音假名”(振り仮名)、“双行夹注”(割書)、“训点”(ヲコト点)、污损等现象的需求,很好地解决了“崩字”转写的难点。该平台的另一亮点是内置调用“みを”和“ふみのは”应用程序编程接口(Application Programming Intetrface, API)的功能,允许在转写过程中直接框定部分区域进行识别。最后,该平台聚集了许多日本民间的历史爱好者,贡献了大量的高质量文本。截至2024年10月,该平台已经累计有3650位用户参与,转写了3400万字以上史料。桥本还曾经邀请日本史学者对该网站上的转写成果进行检验,结果发现正确率达到了98.5%。考虑到“大家来翻刻”的转写文本向全社会公开,并且已经被用于“ふみのは”和“NDL古典籍OCR”两套基于深度学习的OCR的训练,可以认为该平台不仅使一批公开在网上的史料获得了高质量转写材料,更为日本学界发展更高精度的OCR奠定了坚实的数据基础,反映出日本学界在数字化众包领域的巨大成就。
2. 数据结构化领域的实践
在数据结构化方面,日本学界在制作元数据、结构化文本数据、结构化图像数据等具体实践上都有值得讨论的地方。
针对制作史料目录元数据,日本学界摸索出了一套适应国际标准又尽可能保留史料原本面貌的整理方式。以东京大学史料编纂所的实践为例,该机构在编制古文书目录时,应用了由国际档案理事会(International Council on Archives)制定的《国际档案著录标准》[General International Standard Archival Description,ISAD(G)]。ISAD(G)的核心特征在于“多级著录”,即在其著录模型中存在全宗(fonds)、系列(series)、卷宗(file)、单件(item)等层级,其中全宗和系列还可进一步划分出子层级。在整理《岛津家文书》时,东京大学史料编纂所鉴于该文书群是以史料群形式流传而来,其中常常包含册子装和卷轴装的文书史料,还有些文书被装在箱中保管,所以将该文书群作为系列,将各箱作为子系列,将成份文书作为卷宗,最后将具体文书作为单件,从而依照ISAD(G)的原则将数据录入“所藏史料目录数据库”(Hi-CAT)之中。这种整理方法将国际标准同史料实际情况相结合,不仅便于向其他机构提供符合国际标准的数据,提升了数据的可交换性,同时更尊重了史料的原有面貌,与中国古文书学研究者提出的“归户性”理念不谋而合,有助于史料学研究者把握史料情况。
在结构化图像数据方面,日本学界对IIIF(International Image Interoperability Framework)的应用已十分普及。IIIF,即“国际图像互操作性框架”,是一项定义在网络上描述和提供图像的方法及其元数据的国际标准。截止至2018年10月,IIIF已经被国际上超过600家机构采用,日本国内的主要学术机构,如东京大学、京都大学、国立国会图书馆、国文学研究资料、国立历史民俗博物馆等,都使用这一API对外开放电子化图像。IIIF的最大优点在于允许图像公布者之外的其他人利用Presentation API对图像进行引用、注释、改编和再发布。前文所述“大家来翻刻”平台本身并没有存储任何史料图像,所有图像皆基于IIIF标准引用自其他机构。截至2024年10月,该平台至少使用了来自23个机构的数字化图像,甚至包含法国国家图书馆等海外机构,可见IIIF标准在日本学界的普及程度。
但与前者相比,日本学界在录入和共享结构化文本数据方面却显得“雷声大雨点小”。当前针对数字人文领域的文本结构化,最重要的标准莫过于初稿发布于1990年7月的“文本编码倡议”(Text Encoding Initiative,TEI)。然而管见所及,以日本史研究领域为限,目前日本国内应用了TEI标准并对外公开的成果仅有由涩泽荣一纪念财团牵头编辑的《涩泽荣一日记》,以及由日本国立历史民俗博物馆牵头编辑的数字学术版(digital scholarly edition)《延喜式》。当下,两项项目知名度并不高,尚未看到二者有取代传统纸质版材料的迹象。
不过,在法学史研究领域,名古屋大学在日本政府建设的“e-Gov 法令检索”系统以及日本国立国会图书馆“日本法令索引”数据库之外,搭建了“法令文本数据库”。该数据库同既有数据库相比,不仅修正了日期错误,更对“e-Gov”系统所使用的法律标准“XML Schema”进行了扩展,并依照扩展后的Schema录入了1886年以后的所有法令,便于对日本法律进行历时把握。考虑到名古屋大学在其网站上公开了相关XML(可拓展标记语言)数据,所以本文认为这属于较为少见的文本结构化成果。
二、数据发现
当数据被数字化并公开后,数据发现成为为“数据驱动”型研究流程中的下一个步骤。由于数据创建者与使用者的相互分离正成为当代科研中的基本事实,所以如何了解数据、取得数据已经成为众多研究者所关心的问题。即使并不运用统计分析方法的研究者也同样在享受着数字时代各种检索系统带来的便利。目前主要存在三种可供研究者发现并获取数据的途径,分别是图形化检索系统、可通过编程语言调用的API、公开数据集。
1. 史料公开与检索系统
在史料、数据的检索和公开系统方面,日本已在此方面进行了大量建设,并在建设跨机构检索系统等方面颇有成效。尤其自2011年东日本大地震以来,各界人士联合发表了《档案立国宣言》,提出“‘档案’是21世纪日本复苏的钥匙”,以高度的紧迫感大力推进数字化建设。其中最重要的一点是日本政府和学界通力合作,构建跨库、跨机构检索平台的工作。相关成果表2所示。
表 2:日本国内主要的综合性检索系统
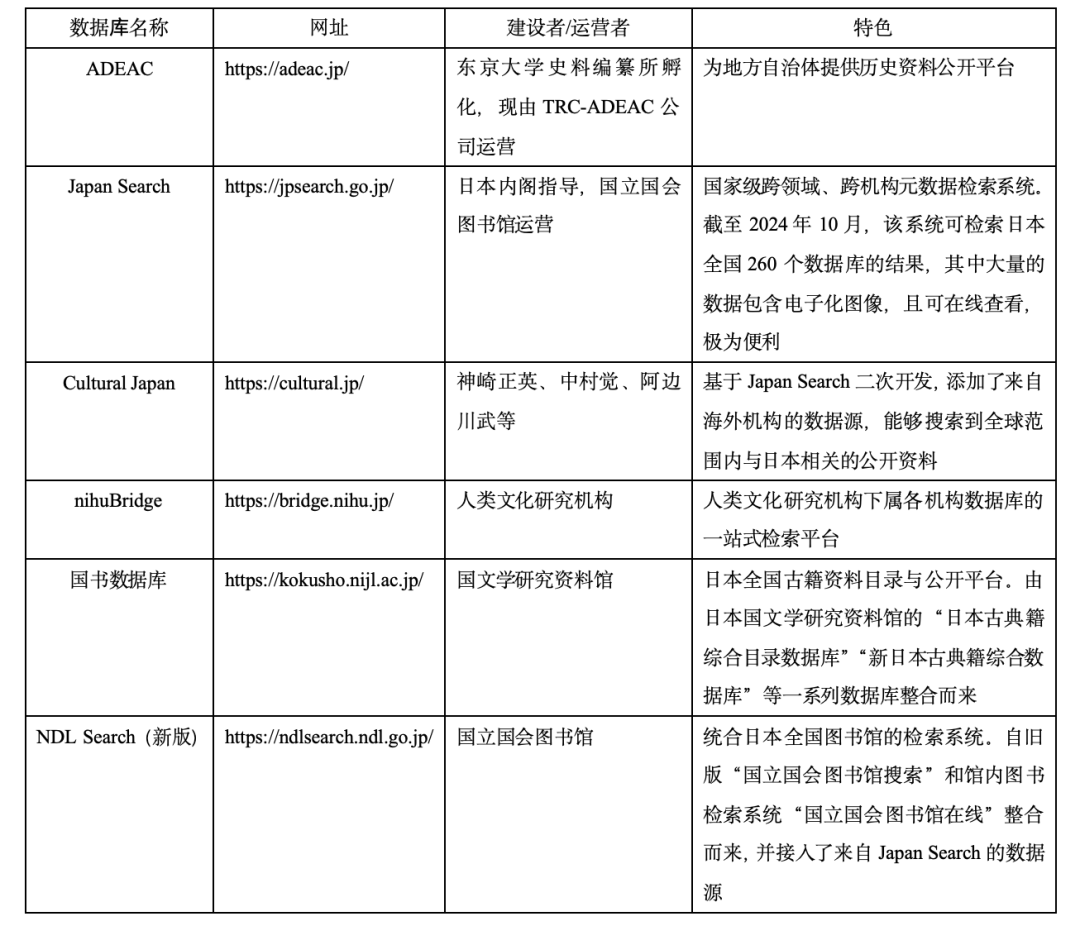
表2中这些检索系统大多运用了同“关联开放数据”(Linked Open Data,LOD)相关的技术,体现了日本国家机构数据的开放化和互联互通化。其中最受瞩目的当属NDL Search。该库不仅能通过和Japan Search以及“国立国会图书馆数字收藏”的信息整合,帮助检索者直接查找包括文书、文物在内的各类史料,更可以通过丰富的馆藏帮助检索者寻找最前沿的研究成果,可谓一站式满足了寻找日本学科研资料的需求。
另一重要动向是各机构对数据库功能的改进和加强,使已有各类数据库不再仅仅是简单的检索工具,而成了拥有史料对照或分析等强大功能的检索系统。日本国立国会图书馆最具代表性。除研究者较为熟悉的“国立国会图书馆数字收藏”外,该馆还建设了以下一系列实验性检索系统或数字人文工具,见表3。
表 3:日本国立国会图书馆开发的实验性工具
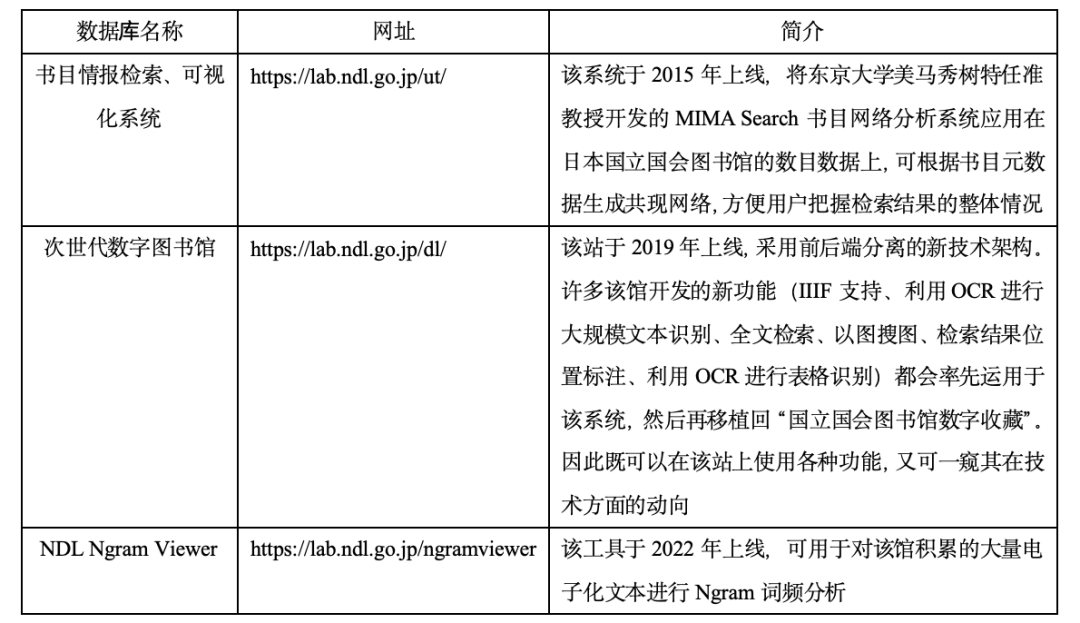
表3中各个工具,反映了日本国立国会图书馆在改进图书馆服务、推动数字人文发展方面所取得的成就,若将以上工具同“国立国会图书馆数字收藏”结合使用,能极大提高检索效率。
除日本国立国会图书馆外,其他机构的动向也值得关注。
东京大学史料编纂所于2022年使用NDLOCR对该机构公开史料集进行了批量识别,在此基础上构建了“史料集页面检索”系统与“幕末维新史料全局检索系统”。利用这两个系统,不仅可以直接检索到关键词在原页面上的出现位置,更可以利用系统自带的Ngram功能进行词频分析。
再如上智大学于2010年开始建设的日本人名数据库(Japan Biographical Database,JBDB),作为模仿中国历代人物传记数据库(CBDB)的产物,近年来曾受到国内学界介绍。不过截至2024年10月该数据库仅包含约1.4万人数据,远远少于一般的日本人名词典的收录量,更无法与拥有53万余人数据(截至2024年2月)的CBDB相比。因此目前该数据库作为人名查询工具的实用性尚且有限,但作为开展社会网络分析研究的基础已经辅助产出了不少学术成果。
此外,佐贺大学的相关实践也值得关注。2018年佐贺大学将《小城藩日记》全文转写,并在此基础上建设了“小城藩日记数据库”。该数据库不仅包含日记的内容,更基于IIIF标准同原史料电子化图像相关联,还利用深度学习技术从日记文本中抽取人名、地名等关键词,实现了通过数字化手段对史料进行精加工的设想。佐贺大学还将佐贺藩内其他藩政日志同《小城藩日记》的数据结合起来,构建了“佐贺藩相关《日记》资料时序数据库”,实现了多种记录史料之间精确到日级别的对照分析。由于目前针对候文这一古代书面文体的自然语言处理(Natural Language Processing,NLP)技术尚不成熟,所以佐贺大学在候文文献上成功实现命名实体识别等任务的实践极具前沿性,值得关注。
2. API和数据集
在图形化检索系统之外,还有另外一种发现数据的方式,即利用编程语言通过API直接请求数据。目前日本各主要数据库均会对外提供RESTful API,各大网站上也都会设置API相关页面,读者可自行查找相关页面学习使用。日本各大机构还积极运用LOD技术栈[如资源描述框架(RDF)和SPARQL]对外提供API。其中与历史学研究相关的API如表4所示。
表 4:日本国内提供SPARQL服务的历史学相关数据库
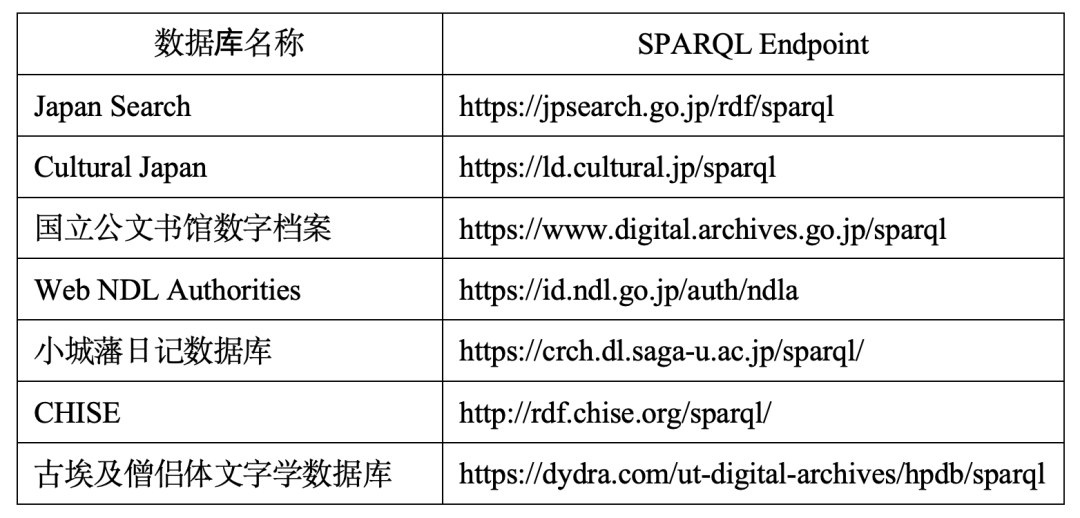
要想使用编程语言从上述数据库获取数据,就要用到SPARQL。SPARQL是专门用来查询RDF数据的协议和查询语言。SPARQL端点则是对外监听用户发来的请求的服务器,用户将SPARQL请求发给端点即可获得返回的数据。SPARQL支持处理异构数据,也支持对数据进行基于图的分析,还将获取数据的决定权最大限度地交给了用户,所以无论是进行下一步的数据分析,还是基于获取的数据进行二次开发都非常方便。若要进行二次开发,那么直接使用SPARQL查询获取数据,还具备保证数据随上游数据源自动更新的益处。考虑到这些优点,日本学界在这方面的建设值得肯定。
此外,日本学界还公开了一系列数据集供下载使用。由于各机构公开的数据极其繁多,以下择要介绍。
深度学习数据集方面,前文所述CODH、国立国会图书馆、“大家来翻刻”、东京大学四方均已积累大量数据,可供训练机器视觉模型。其中CODH推出的数据集最为多样,包含KMNIST数据集、日本古典籍崩字数据集、篆书字体数据集、近代杂志OCR学习用数据集。这些数据均可在CODH的数据集列表页面找到。且由于CODH于2019年在著名机器学习平台Kaggle上发起过崩字识别模型开发竞赛,当时便采用KMNIST数据集作为竞赛用数据集,所以该数据集可在Kaggle上找到并直接应用在自己的模型当中,十分方便。此外,国立国会图书馆、“大家来翻刻”公开的数据均可在各自的Github页面找到。东京大学的崩字数据集则被公开在新设立的“HI Lab”网站上。
历史地理数据方面,以京都大学东南亚地域研究所为主体的“H-GIS研究会”可谓先驱。该研究会与人类文化研究机构合作,于2007年率先制作了“历史地名数据”数据集。此外,筑波大学于2009年进一步制作了覆盖明治、大正、昭和三个时期的“历史地域统计数据”。此后,北本朝展团队集其大成,公开了“《日本历史地名大系》地名项目数据集”“《日本历史地名大系》行政地名变迁数据集”“历史行政区域数据集”。这些数据集使用了二战后编纂的《日本历史地名大系》、前述筑波大学的成果以及日本政府公开的国土数据等数据源作为自己的数据集基础,较H-GIS研究会的成果更加准确、全面。在此基础上,北本团队还启动了GeoLOD、GeoNLP项目,在H-GIS研究会的成果之上进一步构建历史地名数据辞典,为各个地名赋予唯一标识符,且可直接从文本中识别出具体的历史地点。目前该数据集已经进一步衍生出数字人文工具——PyGeoNLP库,可直接在Python语言中安装该库来使用相关功能。
历史经济数据方面,以经济学研究见长的一桥大学与神户大学颇有贡献。一桥大学已将该校各种研究项目中所使用的经济学数据公开。其中最重要的成果,乃将大川一司等人编纂《长期经济统计》电子化后所得“日本长期经济统计数据库”。该数据库收录了经推算所得1868~1940年的日本国民经济各领域的统计数据,曾被用于多种近代日本经济史的编纂,极具学术价值。神户大学则以1787~1871年三井家大阪汇兑店的《日记录》为基础,获取了精确到天的天气、米价、金银汇兑率变动数据,建设了“近世经济数据库”。该数据库的数据是研究近世经济情况的一手史料,其学术价值同样弥足珍贵。
从以上数据集的公开化可以看出,日本学界在开放数据、打造数字人文工具,开展历史地理学、经济史的数字人文研究等方面有较多积淀,成果可圈可点。但一些重要领域仍然缺乏相关数据集,如仍然鲜见带标点的候文或变体汉文语料数据集,更没有候文与现代日语相互对照的数据集。这些前近代语料是在相关时代的史料上实现各种NLP任务的基础。缺少这些语料,就难以有效构建帮助研究者针对前近代文本进行文本挖掘的工具。
三、数据利用
在数据驱动型学术生产过程中,位于流程终点的环节是数据利用。由于数字人文研究中所使用的“数据”通常采用机器可读形式,并不适合人类直接阅读,为了实现其社会效益,就必须以特定方式进行利用。一种方式是将数据运用于研究,通过分析数据得出结论以产生学术价值。具体而言,是运用统计学方法和可视化技术,抽取人类能够理解的统计学指标,或者制成能够被人直观把握的图表,由此得出结论。另一种则是将数据运用于教育与传播,通过数字手段提高历史学的社会效益,促进历史学的自我维持与发展。这种方式多抽取数据中可供展示的部分,辅以精美的前端程序,促进成果的大众传播。
1. 数据分析工具及相关实践
在研究方面,当代日本学界分析数据的手段主要集中在文本挖掘、地理信息系统(GIS)和时间信息系统三个领域。
首先,在文本挖掘领域,日本最流行的工具是樋口耕一开发的KH Coder。该软件于2001年发布,系针对非结构化文本的计量文本分析与文本挖掘工具。与国际上的同类软件Voyant Tools相比,该软件具备类似的词频分析、文本分析、生成词汇共现网络的功能,同时内置了Mecab和Chasen等日语分词工具,对日语有更好的支持。但该工具主要被运用在社会学等学科当中,日本史学领域的研究很少使用该工具。究其原因,很大程度上在于当代日本史学研究已经高度实证化、精耕细作化,强调对关键史料进行精读、细读。这使得长于大规模文本分析的计量方法很难有用武之地。
但当下的日本数字人文学界已经清楚地认识到了这一问题。而为了纠正这种“一面倒”偏重精度、细读的倾向,不仅需要引入计量分析的方法,还要进一步开发新的研究工具。2021年,鸟居克哉等人使用潜在狄雷克利分配(Latent Dirichlet Allocation,LDA)算法分析了镰仓时代的《民经记》,展示了主题的历时性变化、主题与人物和语句的关系,并提出要在该算法的基础上建设新的更适合日本史学者使用的新工具。随后在2024年,山田太造团队启动了“构筑基于史料数据感知的日本列岛记忆继承模型”项目,提出要打造应用了OCR、LDA算法、BERT模型等技术的数据分析基础。该项目目前刚刚启动,后续值得期待。
另外,前近代日本史研究中还存在另一个“阻碍”运用文本计量分析方法的因素,即针对候文、变体汉文等前近代书面文体的NLP技术尚不成熟。当前KH Coder所使用的MeCab和ChaSen两种分词器均仅默认支持现代日语。若想对古日语进行分析,则需手动更换词典,且分词效果较差。2021年,古贺夏子等人提出可以利用深度学习辅助命名实体识别,并通过众包手段收集训练数据,并通过微调(Fine-tuning)Flair模型,实现了候文命名实体识别任务。尽管这一成果具备一定的前沿性,但是由于古贺等人没有放出任何模型供外部使用,使得其成果对其他研究者并无太多帮助,对领域前沿发展的推动也非常有限。目前,日本的NLP研究者大多把精力放在研究现代日语或者汉文身上,忽视了对前近代各种介于汉文和日语之间书面文体的研究,造成此类文献难以直接应用文本计量分析方法。可以认为,当前日本学界在基础领域的“缺课”已经拖累了数字人文实践在文本挖掘领域的深入发展。
与发展迟滞的文本挖掘领域相比,日本历史和地理学界早已开始运用GIS,并取得丰硕成果。在工具方面,尤以谷谦二开发的MANDARA引人瞩目。该软件较QGIS等软件功能较弱,但在诞生初期打破了外国昂贵GIS软件的垄断,目前仍凭借简单易用为日本学界广泛使用。在历史地理学研究领域,GIS主要被用于古地图精度验证和景观复原研究。2014年,平井松午、安里进、渡边诚利用现代GIS验证近世古地图的精度问题,指出近世城下町绘图是以管理宅邸土地为目的制作而成,未必能正确反映土地利用的实际情况,且同一张古地图的精度并不均一,地图各部分的误差、扭曲程度各不相同。另外,2022年塚本章宏将高分辨率的“伊能图”输入GIS系统,并在此基础上统计标注出当时编纂者使用的针眼,从而比较各种伊能图之间的精度差异。而平井松午则在其编《近世城下绘图的景观分析、GIS分析》中利用GIS来分析城下町的景观变化,以及身份制同城市空间构造之间的关系。
在时间信息系统领域,“HuTime”及配套组件值得一书。该系统由关野树自人类文化研究机构开发的“GT-Time”改进而来。包含以RDF格式公开的API、历法转换服务、时间轴制作软件“HuTime”三部分,可将儒略历、日本历、伊斯兰历、犹太历、泰国佛历等历法相互对应。目前该系统的时间API有着可将各种数据库内容同时间信息关联起来的特点,所以得到了日本学界的广泛应用(前述“小城藩日记数据库”便使用了其API)。不过HuTime软件依然缺点明显。2012年,后藤真曾尝试基于TEI标准,将《续日本纪》这一奈良时代的基本史料结构化,并提取其中的时间和空间相关数据导入HuTime进行分析。他指出HuTime具备能够轻松把握史料整体面貌的优点,但很多时间、地点暧昧不明的数据难以录入。未来HuTime仍需继续提高易用性,并解决模糊数据处理问题。
2. 基于数据的历史教育活动
除了上述以科研为目的的数据利用活动,教育与传播领域同样需要数据。公开数据将学界和民众联系在一起,能创造出良好的社会效益。最经典的例子,莫过于日本学界、政府、民间爱好者在制作历史地图方面形成的互动。
2005年,谷谦二开发了近现代日本地图对照软件“今昔地图”。2013年,在前者基础上,网页版“今昔地图”问世。该软件方便易用,被广泛用于日本高中教学,甚至被写入中学教材。谷谦二于2022年去世,为了让他的“学术遗产”继续运行,东京大学空间信息研究中心(Center for Spatial Information Science,CSIS)与遗属及日本国土地理院达成协议,将其网站数据移动到东京大学的服务器上继续公开。2023年,来自东京地区多所高校的研究者组成研究小组,向“今昔地图”网站补充更多原本未收录的古地图数据。2024年,落合谦次进一步收集了“今昔地图”网站的数据以及其他公开数据,搭建了“open-hinata”Web GIS工具平台。该平台提供的图层种类、数量繁多,可将近世、近代古地图数据层同其他图层叠加。该平台的出现不仅有助于民间知识传播,更有益于学界进行知识再生产,是多方互动的典范。
另外,在崩字的众包转写方面,公开数据也被用于面向公众的教学活动。桥本雄太曾于2015年开发了崩字学习软件“KuLA”。该软件提供各种变体假名、汉字的崩字图像、解说和用例,还设计了辅助记忆这些假名、汉字的测试页面。软件中使用的古籍图像全部来自网络数据库的公开图像。该软件一经上架便获得了良好反响。该软件进一步激发了民众向学界建设的众包平台贡献更多公开数据的热情。桥本对“大家来翻刻”平台的用户的问卷调查结果显示,约70%的回答者表示曾经使用过KuLA。可见KuLA起到了为众包项目吸引和转化潜在的参加者的作用。由此可知,向民众传播与展示公开数据对促进学界和民间良性互动具备积极意义。
结 语
2010年,由日本历史学会主办的刊物《日本历史》推出了“日本史研究与数据库”特辑。在横山伊德撰写的卷首语中,他再次强调了自己一直以来的看法,即使用计算机并没有带来一种与既存实践有本质上区别的历史学。但作为通过互联网,积极利用西方史料研究近世史而闻名的学者,他也呼吁拥抱网络社会发展的潮流,期待日本史领域数据库的革新。
如今,随着日本数字人文实践的持续深入,横山伊德的那些期待已基本实现,并且他所没有预料到的情况也出现了:以数据收集、存储、分析为中心活动的“数据驱动”方法论正呼之欲出,使得日本史学领域出现了一批专注于数据库建设、数据分析的数字人文研究者。新兴的“数据驱动”范式,其内涵已经超越了建设数据库的范畴,而成为一种强调数据流动、崇尚开放共享、服务研究需求的新实践,以及在新的时代条件下推动人文学科发展的新增长点。
“数据驱动”范式的出现,对于中国的日本史学界而言,或许也是新的发展机遇。随着日本学界数字化水平的提高,如今获取日本史料图像等数据的门槛显著降低。除此之外,诸如IIIF、TEI、RDF等国际技术标准及其相关工具链已形成丰富生态,为数字人文实践提供了成熟的技术条件。以大语言模型(Large Language Model,LLM)为代表的人工智能浪潮则更降低了人文学者编程的难度,并揭示了构筑新型辅助工具的可能。更加重要的是,近20年来日本数字人文新范式的形成得益于政府的统筹推动及社会各界对数字化发展的广泛共识。故此,若能把握机遇,在政府、学界、民间力量之间构筑共识,加强协作,必能建设起统一且自主的基础设施,必将一定程度上改善国内日本史科研与教学的基础条件,营造出数据驱动型的研究环境,促进中国日本史研究的全面高质量发展。
本文选自2025年社会科学文献出版社出版《日本学研究(第39辑)》论文节选,摘要、内容与注释略有删改,如需引用请参见原书。
作者:王侃良,浙江工商大学东西文明互鉴研究院副研究员,数字人文(重点)实验室执行主任;战林泽,山东大学历史学院硕士研究生。
审核:
编辑:
排版:
江
静
王侃良
黄伊诺
本篇文章来源于微信公众号: 浙商大东亚研究